too many /ttj requests
It started with a New Relic Alert - Disk Full
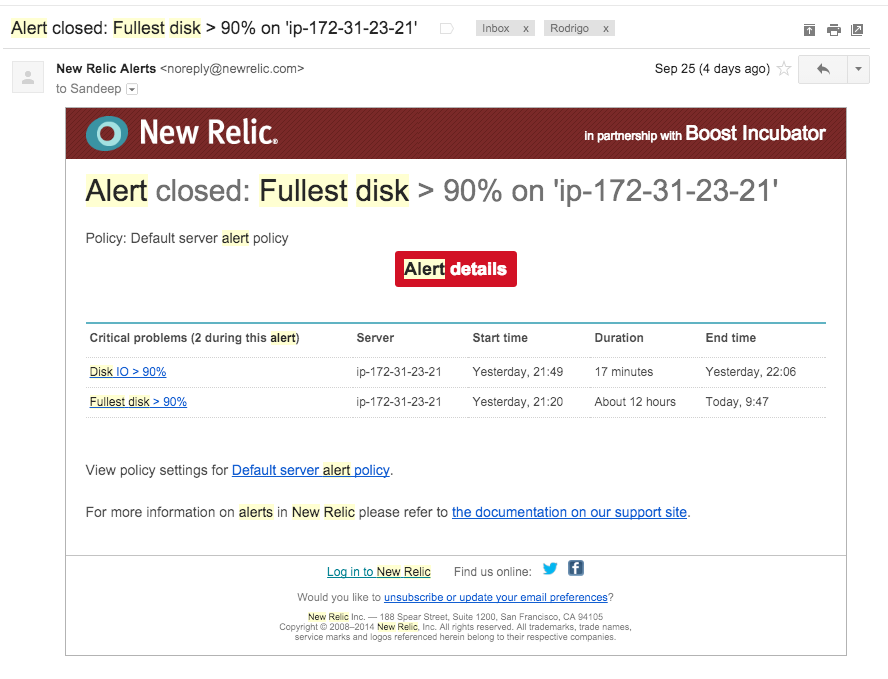
So my first step was to SSH in to production box via Cloudd66 toolbelt.
A simple df showed that the hard rive was indeed full.
I ran my handy script to find the biggest files on the system.
find . -printf '%s %p\n'| sort -nr | head -10
The nginx access.log file was over 2GB huge. So i did, what I knew, deleted the file. The unicorn.stderr.log was also over 2GB.
rm $STACK_PATH\log\unicorn.*.log
rm /var/log/nginx/*.log
45 minutes later, I got another notification from New Relic saying that the logs were full. At this point I knew something was wrong as the hard drive should not fill up in less than 45 minutes. So I think its time, to open up the log and see what is it logging
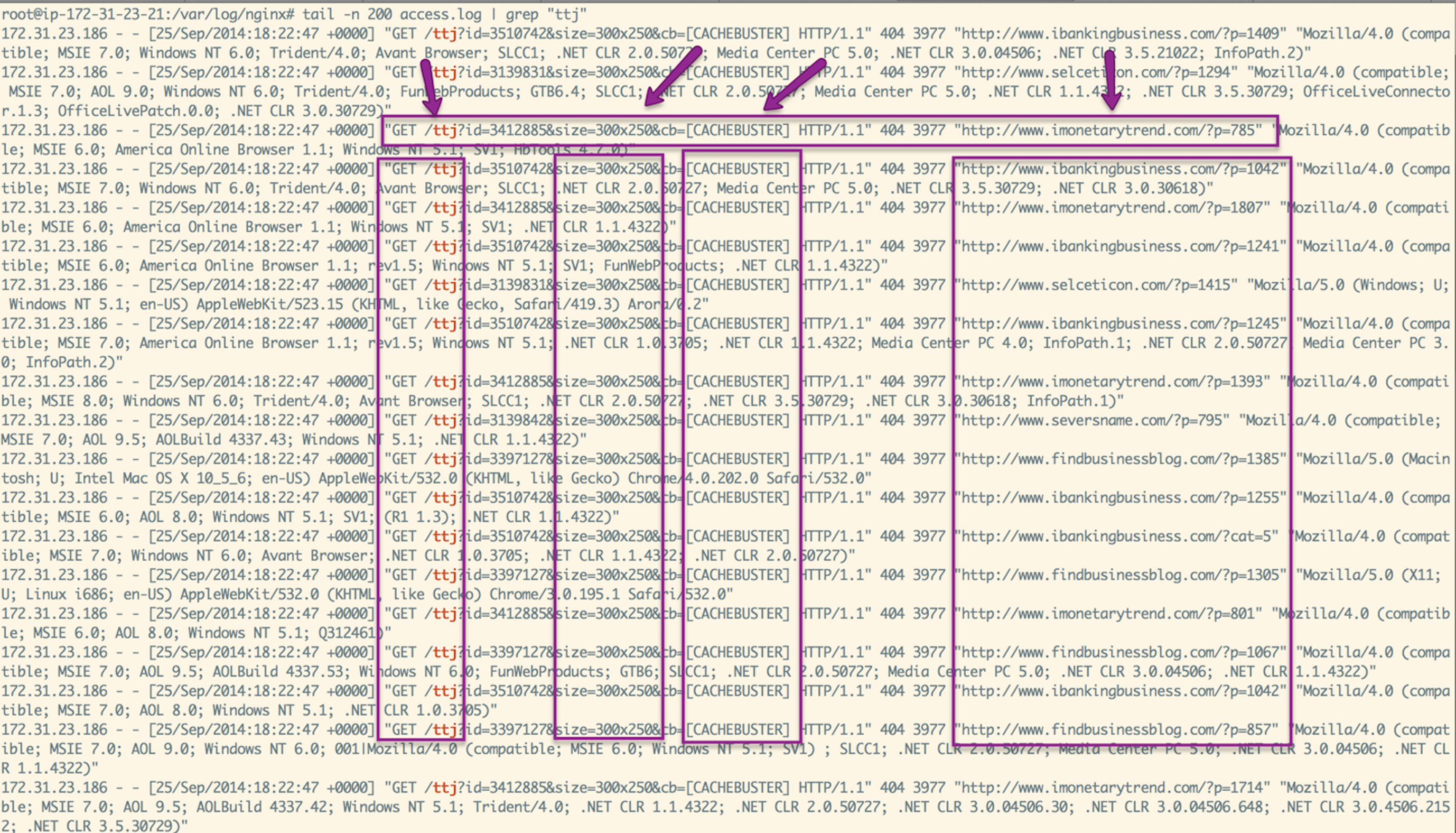
It seems like i am getting 10K+ per minute requests for a /ttj file and its logging a 404. This is very strange as I don’t have any /ttj resource and this just started to happen. This seems like DOS attack to me.
Amazon ELB monitor shows that as of yesterday our
load balancer has being encountering this spike of /ttj requests.
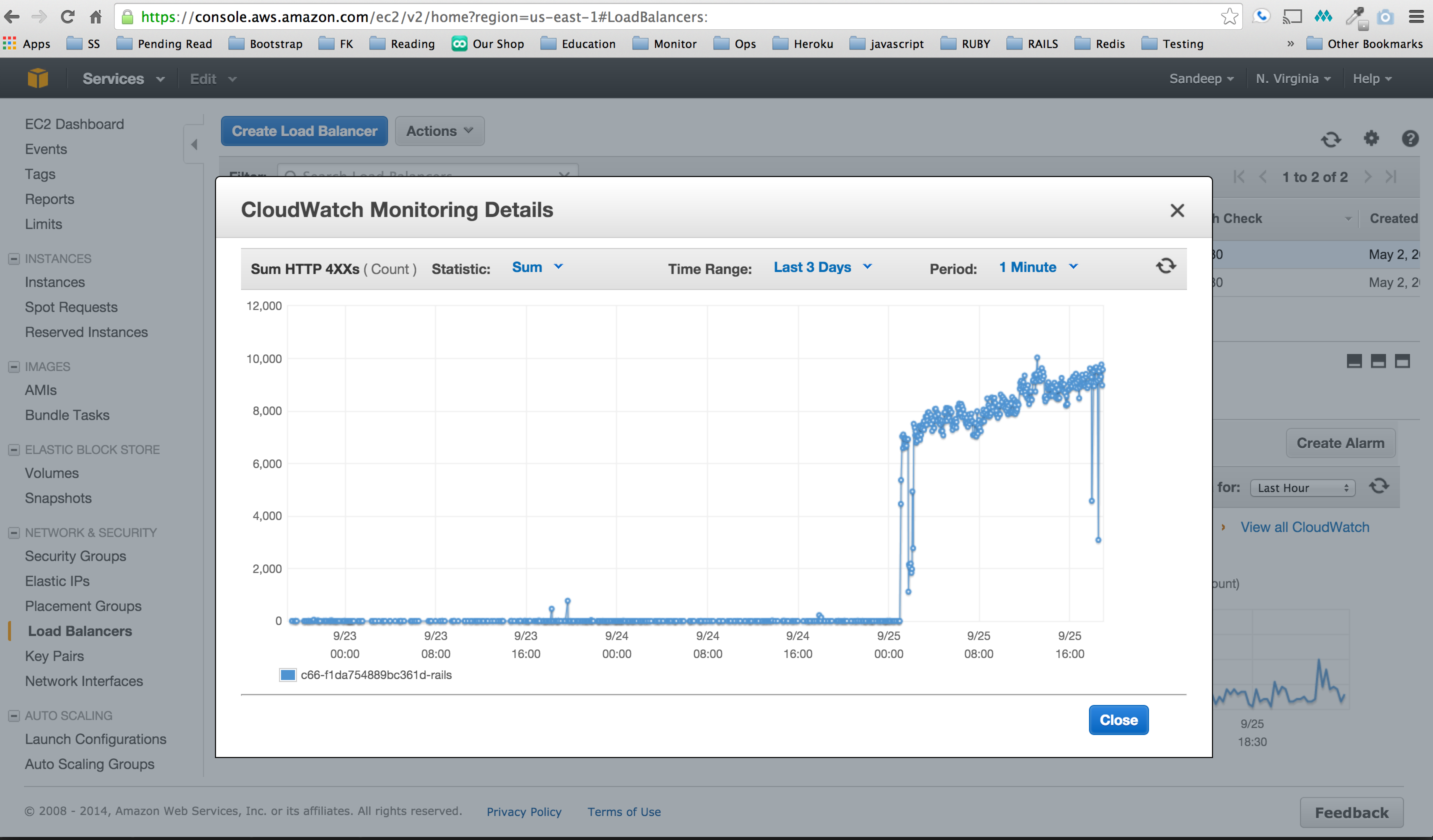
Now I need to know is this indeed a DOS attack, where these requests are coming from and so on.
To see the source IP address I updated my nginx.conf located at /etc/nginx/cloud66_nginx.conf. Now the logs reveal the source IP rather than the load balance IP.
log_format varnish_log '$http_x_forwarded_for - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent "$http_referer" ' '"$http_user_agent"' ;
access_log /mnt/log/nginx/access.log varnish_log;
Now my logs looked had the source IP:
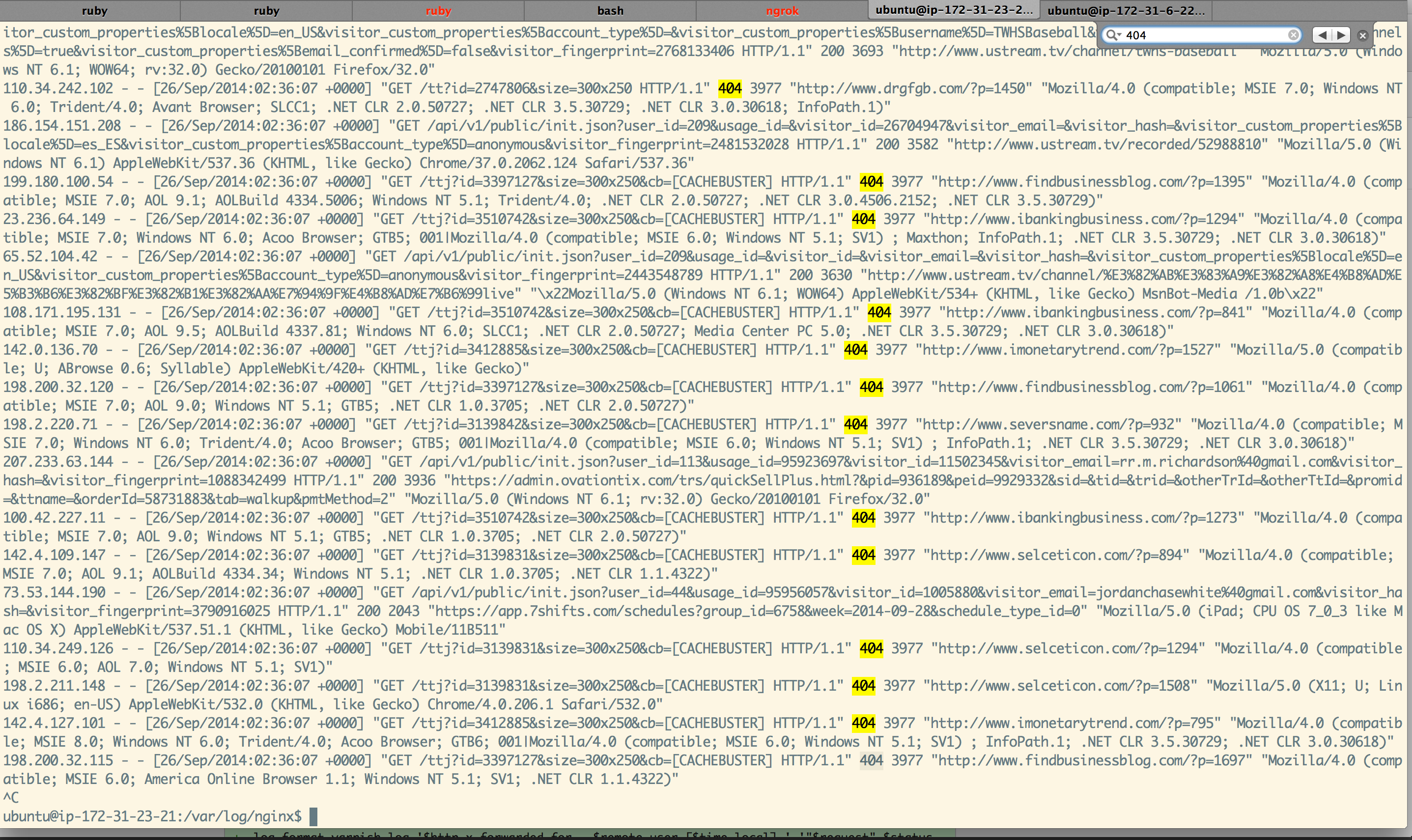
It seems like these requests are coming from a variety of reputable websites, various IP addresses spread across the globe. Seems unlikely that these guys are collectively doing anything malicious.
Now, its time to bring in AWS Support. After going back and forth with AWS round the clock kick ass awesome support, I knew exactly what was happening:
Apparently Amazon made an executive decision that it should scale up our Load Balancer without letting us know. This caused us to get a new Public IP address. This IP Address was previously being used as proxy and now that we had that IP address we were getting this requests. Amazon Support was nice enough to give me a new IP Address and resolve the issue.
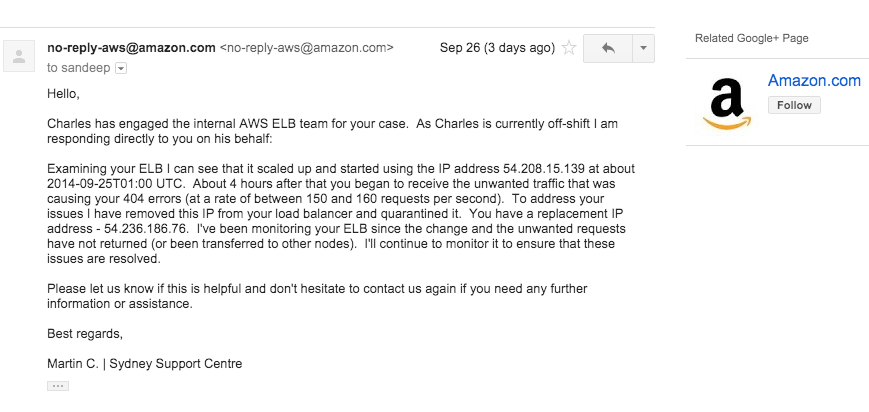
For now this problem is at rest. Next steps, which I have covered in a separate post would be to better defend my app so its less susceptible to something like this.